![たね[どっと]いんふぉ](https://tane.info/wp-content/uploads/2021/12/tanehomefixed8.png)
ちょうど読めそうな絵本を探すには

NTTの藤田早苗です。
この連載ではNTTで取り組んでいる絵本検索システム「ぴたりえ」関連の研究を中心にご紹介していきます。
絵本を探すとき、子どもの年齢にあった絵本や、もっと言えば「わが子が」ちょうど読める絵本を探したいと思ったことはないでしょうか?
私はあります!
図書館でずらりと並んだ絵本(しかもほとんど背表紙が見えているだけ)の中から、わが子が持ってくる絵本は、赤ちゃん向けすぎて物足りなかったり、自分で読みたいのに難しすぎて読めなかったり。。。 ちょうど読めるくらいの絵本を簡単に探せたら楽なのに!と思っていました。
今回(第3回)では、そんな要望を実現するために取り組んだ、絵本のテキスト(文)の難易度推定についてご紹介します。
出版社が付けた対象年齢 ~実はあまりつけられていません~
絵本の難易度推定をすると言うと「でも、対象年齢は出版社がつけていますよね?」と言われることがあります。確かに対象年齢が書かれている絵本もありますが、NTT絵本・児童書コーパス(本連載第2回参照)で入力が完了している7,132冊を調べたところ、本に対象年齢が書かれていたのは2,167冊(30.4%)のみでした。しかも、対象年齢が書かれていた場合でも、「3歳から小学校初級むき」「乳児から」「4才から」といった書き方が多くて年齢の幅が広く、表現も出版社によってまちまちでした。
もちろん、どの本を何歳で読んでもいいですし、子どもの発達はいろいろですから、何歳向けと限定するべきでないという考えにも同意できます。でもやっぱり、年齢や難しさで絵本を探したいときもあるし、探したかったのです(少なくとも私は)。
そこで我々は、すべての絵本に対し、同じ基準で機械学習によって難易度推定を行うことを目指しました。
難易度推定 ~テキストの難しさを決めるもの~
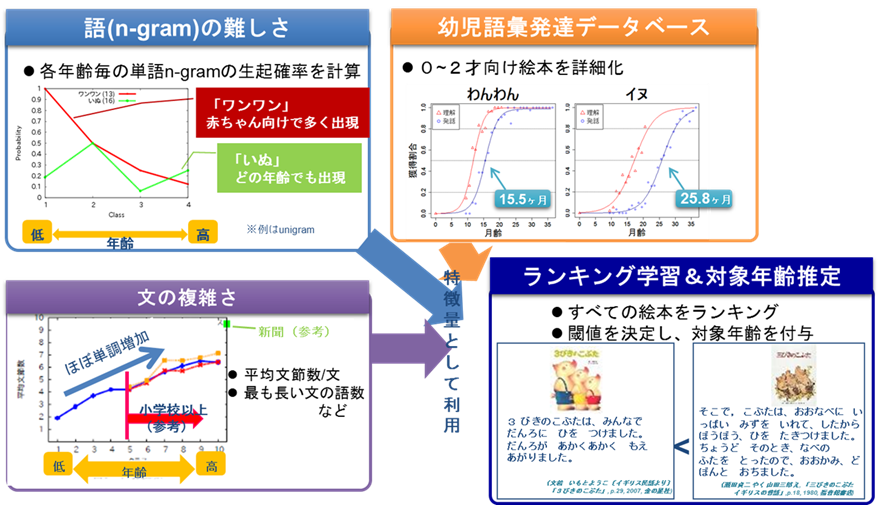
機械学習で難易度を推定するためには、(1)学習や評価に使うための正解データと、(2)利用する特徴量(対象データの特徴を定量的な数値として表したもの)を決める必要があります。
まず、正解データとしては、対象年齢が比較的はっきりしている絵本を用いることにしました。例えば、福音館書店のこどものともは、比較的細かく対象年齢が設定されています。こうした絵本を正解データとして利用し、実験と評価を行いました(文献[1])。
次に、利用する特徴量を決める必要があります。
そもそも、文の難しさは、何によって決まるのでしょうか?
我々は、出てくる語の難しさと、文の長さや複雑さの両方が影響すると考えました。
そこで、語の難しさを反映する特徴量として、「何歳向けの本でよく使われる語か」を表す特徴量と、「幼児がその語をいつ頃発話できるようになるか」(文献[2])といった特徴量を使いました。また、文の複雑さを反映する特徴量として、平均文節数や最も長い文の語数などを使いました。
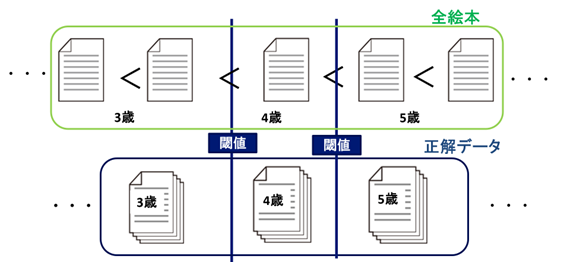
これらを特徴量として利用し、ランキング学習を行うことで、すべての絵本をやさしい順(難しい順)に並べることができるようになりました(図1)。
これにより、おなじお話の絵本でも、どちらの絵本の文の方が難しいかを推定できるようになりました。例えば、2冊の「3(三)びきのこぶた」の同じシーンをご覧ください(図2)。この2冊の絵本は、難易度推定の結果、右の絵本の文の方が難しいと推定されました。見比べていただくと、皆さんも、右の絵本の方が難しいと感じるのではないでしょうか?

もう1例、「はみがき」に関する絵本を例にご紹介します(図3)。この例でも、右の絵本の方がより難しいと推定されました。この例でもやはり、皆さんも、右の方が難しいと感じられるのではないでしょうか? このように、我々の難易度推定により、あるテーマで取り出した絵本をやさしい順(難しい順)に自動的に並び替えることができるのです。

わが子が読めそうな絵本を探す ~今読める絵本に近い難しさ~
ここまでくるともう少しです。まずは年齢で探せるようにするため、やさしい順に並べた絵本に対象年齢を付与します。我々は、正解データに付与されている対象年齢を参考に閾値を設定し、その閾値より難しければ何歳、といった形で対象年齢を推定しています(図4)。これにより、90%近い精度で対象年齢をあてられており、非常に高精度だと言えます。
もちろん子どもの発達はいろいろです。対象年齢は便利ですが、理想的には「わが子が」ちょうど読める絵本を探したいのです。
そこで「ぴたりえ」では、子どもが今気に入っている絵本を元に検索し、難しさが近い絵本を選ぶことができるようになっています。つまり、「わが子が」今ちょうど読めそうな絵本を探すことができるのです。
ここまで、絵本の難易度推定についてご紹介してきましたが、もちろんこの手法は絵本以外にも適用できます。我々の手法を教科書に適用し、教科書の学年が推定できるか評価したところ、絵本以上に高精度に推定ができました。データがあまりないため児童書や一般書籍では評価できていませんが、少なくとも教科書の学年推定は非常に高精度にできたことから、もし出版社さんにご協力いただけて、テキストデータをいただけるのであれば、児童書や一般書籍でも同様の難易度推定と推薦が可能だと考えています。
もちろん、英語の絵本でも同様の難易度推定が可能です。我々は英語絵本を推薦するシステムも構築し、学校での英語多読支援の実証実験をすすめています。
次回(第4回)は、好みの絵の絵本を探す方法についてご紹介予定です。
参考資料
[1] 藤田 早苗, 小林 哲生, 南 泰浩, 杉山 弘晃. “幼児を対象としたテキストの対象年齢推定方法”, “Target Age Estimation of Texts for Children”, 認知科学, Vol 22, No. 4, pp. 604–620. 2015.
[2] 小林哲生, 奥村優子, 南泰浩. “語彙チェックリストアプリによる幼児語彙発達データ収集の試み”, 電子情報通信学会技術研究報告, 115(418):1-6, 2016. (HCS2015-59).

0 Comments