![たね[どっと]いんふぉ](https://tane.info/wp-content/uploads/2021/12/tanehomefixed8.png)
絵本検索システム「ぴたりえ」と絵本電子データ化

NTTの藤田早苗です。この連載ではNTTで取り組んでいる絵本検索システム「ぴたりえ」関連の研究を中心にご紹介していきます。NTTでどうして絵本?と思われる方も多いと思います。そこで、第1回では、そもそもどうしてこのような研究を始めたか、から、絵本のデータ化の方法を紹介します。
「ぴたりえ」を作るきっかけ ~絵本さがしは難しい~
私事で恐縮ですが、私には子どもが3人います(娘2人と息子1人)。子どもって兄弟でも全然違うものですね。本好きになってほしいと思い、寝る前の読み聞かせを心がけていたのですが…。
好きな絵本を持ってこさせると、娘達は物語の絵本を持ってくるのに、息子は恐竜図鑑を持ってくるのです。正直私は恐竜にはまったく興味がありませんでした。それなのに、毎晩、延々と、恐竜の名前、体長、生きていた時代や地域を読まされるのです。おかげ様でずいぶん恐竜には詳しくなったと思います。でも私はせめて図鑑ではなく物語を読みたいと、図書館で恐竜の出てくる絵本を片っ端から借りて読んだのですが、ほどなく読みつくしてしまいました。しかも、図書館にある恐竜の出てくる絵本と図鑑を(おそらくすべて)読み切ったら、息子はもう図書館には行きたがらなくなりました。あせった私は、まだ読んでいない恐竜の絵本があるかもしれない、絵本でなくてもいいかもしれない、恐竜じゃなくても古生物やモンスターも好きかもしれない、と、息子が興味を持つかもしれない、読めるかもしれない本を探して図書館をさまよいました。ところが、図書館の何万冊もの本の中から、息子の興味を引きそうでちょうど読めそうな本を探すのは簡単なことではありませんでした。
この経験からできたのが、絵本検索システム「ぴたりえ」です(図1)。一人ひとりの子どもにあった読みやすさで興味のありそうな内容の絵本を簡単に探せるように、と、作りました。
「ぴたりえ」は2019年にNTTデータ九州社から商用化されました。福井県立図書館や石川県立図書館、幼稚園などでもすでに導入していただいています(お近くの方はぜひお試しください!)。いずれ全国津々浦々の図書館や保育園・幼稚園で使っていただけるようになって、絵本の読み聞かせに悩む親御さんの一助になれば、と、願っています。

絵本コーパスの必要性 ~あればうれしいことがある~
ところで、ここまで読んでくださった方は、私はシステム開発者か何かかな、と思われたかもしれません。が、残念ながら違います。私はNTTコミュニケーション科学基礎研究所に所属する研究員で、専門は自然言語処理(日本語や英語といった自然言語を機械で上手く扱うための研究分野)です。
自然言語処理には、機械翻訳、情報検索、対話システム、難易度推定などの研究も含まれます。すそ野の広い研究分野ですが、一つ大きな前提条件があります。それは「コーパス(=実際に使用された言語表現を集積、整理した言語データ(「言語情報処理 用語集」の「コーパス」の項を参照) )を使う」ということです。つまり、絵本を対象とするためには、絵本のコーパス、それも電子コーパスが欲しいのです。でももちろん、絵本のコーパスなんて存在しませんでしたから、まずは絵本のコーパス作成から始めるしかありません。
世の中に絵本のデータベースはいくつか存在しています。例えば鳴門教育大学で公開されている子どもの心を理解するための絵本データベースや、図書館の蔵書データベースも存在します。こうしたデータベースには、書誌情報やあらすじ、主題などの情報が収録されている場合がありますが、本文がそのままデータ化されていることは通常ありません。
そもそも本文をデータ化する必要ってあるの?と、疑問に思われる方もおられるかもしれません。でも「間違いなく必要です!」少なくとも自然言語処理的には。
人手で付与したあらすじや主題は、それはそれでとても役に立つと思います。でも、本文のデータがあればできることは飛躍的に増えます。絵本にはどんな語が出てきているのか、どのような構文がよくつかわれるのか、大人向けの文章と同じところ、違うところはどこか。推薦方法だって何通りも考えられます。絵本と言語発達の関係の研究にも役立ちそうです。
折しも2010年、著作権法の改正により「電子計算機による情報解析を行うことを目的とする場合には、必要と認められる限度において、記録媒体への記録又は翻案(これにより創作した二次的著作物の記録を含む。)を行うことができる」ようになりました(第47条の7)。2018年にはさらに改正されて、情報解析のためならば「いずれの方法によるかを問わず、利用することができる」ようになっています(第30条の4)。
つまり、著作権者に個別に許可を取らなくとも電子データ化して情報解析に利用できるようになったのです。そこで我々はさっそく絵本の電子データ化を開始することにしました。
電子データ化の方法 ~ひたすらがんばる~
ここからは、具体的にどのように絵本のコーパスを作っているかをご紹介していきます。
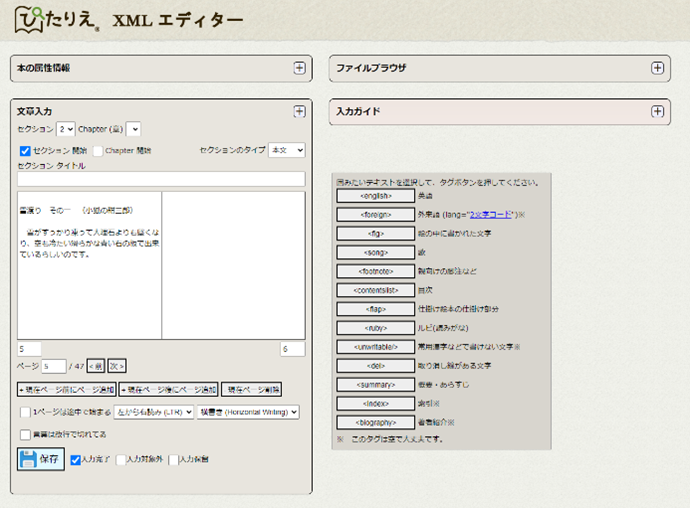
書誌情報はともかく、本文の電子データ化の方法は試行錯誤しました。絵本は絵の中に文字があることが多く、また、文字自体も飾り文字や手書き文字など凝っていることが多いので、OCRが難しいのです。また、そもそもOCRにかけるためには本文の画像データが必要ですが、当然そんなものはありません。結局、ほとんどの本文テキストを人手で入力するという地道な作業を行うことになりました。
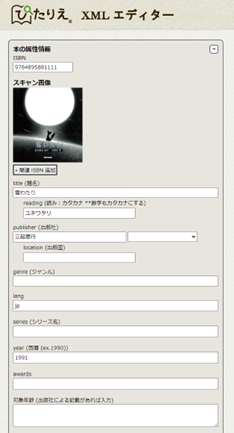
入力用のエディタも構築し、ひたすら頑張って入力しています(図2,3:『雪わたり』宮沢賢治 原作, 方緒良 絵, 1991, 三起商行の例)。(文字が多いものはOCRも利用しています)
地道な努力の結果、2022年7月6日現在、NTTの絵本コーパスは、日本語約7,000冊・英語4,000冊という、世界に類をみない規模になりました。しかも今でも拡張中です。
第2回以降は、絵本コーパスを構築したからこそできた解析結果等をご紹介していきます。
参考資料
藤田早苗, 平博順, 小林哲生, 田中貴秋. “絵本のテキストを対象とした形態素解析”, “Japanese Morphological Analysis for Picture Books”, 自然言語処理, Vol. 21, No.3, pp. 515–540, 2014.


0 Comments